
Introduction
Log files are a crucial tool in the development and maintenance of software programs. This is especially true in the client-server software architecture where servers often need to provide services to hundreds of concurrent requests. Due to the fact that they contain detailed information about the actions taken by a program, log files can be used for a variety of purposes (Lurie 2009, Wei 2013):
- Tracking down problems within a complex system
- Monitoring applications that have little human interaction
- Maintaining detailed records of every request to the server
- Measuring the time or size of requests
During my apprenticeship, I wrote a simple logging system to track requests and responses in a Java server. I quickly learned that a logging system required a good design that would ensure that log messages did not clutter the business logic of the code. I summarized my initial findings in a previous blog post. After further research on the design of logging systems, I decided to write a followup post comparing the use of two design patterns in logging systems.
Code snippets are included to give concrete examples of the design patterns and their implementation in a logging system. These code snippets are written in the Swift programming language and can be run in an Xcode playground (simply copy and paste the code). A full GitHub repo with links to all of the examples can be found here.
A Naive Implementation
Since log files are just console messages or text files that are updated every time a server performs some action, it is tempting to implement a logging system using only the built-in I/O functions in a language. For example, suppose I want to update a log every time a specific method is called. I could simply print a line out to the console or write to a file after the method completes.
It can become tedious to keep track of dozens of println statements scattered throughout the code. The individual messages can be encapsulated in a single Logger class and called when a specific action takes place.
This naive implementation of a logger might work in a (very) simple project. Specific messages can be added in or commented out with little effort, so it is a great way to implement a sophisticated variation of printf debugging (Dassen 1999). The problems with this method becomes readily apparent when one needs to implement a logging system that writes data to multiple sources. For example, suppose you wanted to write a log statement to both the console and a text file. The solution might be to add a second logging statement below the first.
But suppose I want to write logs to many different destinations. Alternatively, suppose that different logging systems need to record data in different formats. The code will quickly become unreadable due to the list of logging statements that follow an important action.
Continuing in this fashion, there would be more lines of code to implement logging than business logic! Luckily, one can implement a better logger through the use of a common design pattern.
The Observer Pattern
The Pattern
The Observer Pattern can provide a structure to organize the logging system from above. The Source Making blog provides a nice description:
Define an object that is the “keeper” of the data model and/or business logic (the Subject). Delegate all “view” functionality to decoupled and distinct Observer objects. Observers register themselves with the Subject as they are created. Whenever the Subject changes, it broadcasts to all registered Observers that it has changed, and each Observer queries the Subject for that subset of the Subject’s state that it is responsible for monitoring (Source Making, Observer, 2017)
In our example, when a server is initialized, one assigns it a list of “observers”. These observers can be hard coded in the server class (as with my code snippets) or can be passed in through dependency injection. When the server performs an action that requires a logging statement, it sends out a notification to each observer on the list. This notification details the action that took place along with any other necessary information (e.g. a port number or a url). Each observer would then independently write to a log file.
A UML diagram of the pattern is shown below (Wikimedia, Observer, 2010).
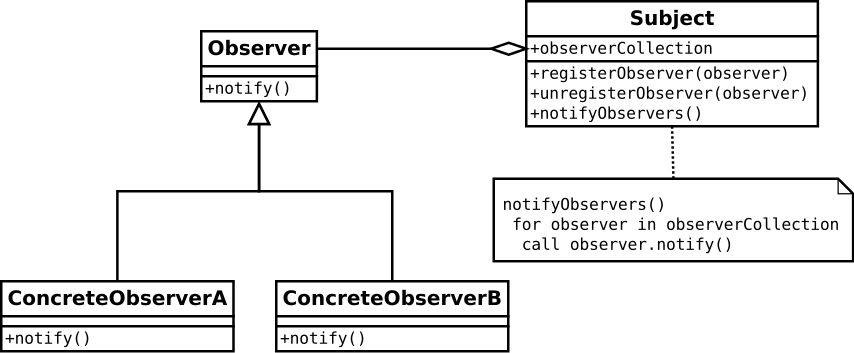
Notice how all of the concrete observers follow the Observer protocol. This means that Subject can contain an observerCollection consisting of objects that follow the Observer protocol (ensuring polymorphism of the observers).
Logging Implementation
The FakeServer class is initialized with a list of observers (either hard-coded or through dependency injection). The server is provided with a notifyObservers method that will loop through each of the observers and send a notification that an important event has occurred.
If more information is required by the loggers (e.g. port number, flags, or client information), a list of variables can be provided. In the example below, I provide a flag to the observers. Each of the loggers can interpret the flag according to their own conditional logic.
Notice how the logging logic has been removed from the FakeServer class and is handled by a different object. This enforces the Single Responsibility Principle in the server (Martin 2008).
The Chain-of-Responsibility Pattern
The Pattern
The chain-of-responsibility pattern can also be used to implement a robust logging system. Once again, the Source Making blog provides a definition of the pattern:
The pattern chains the receiving objects together, and then passes any request messages from object to object until it reaches an object capable of handling the message. The number and type of handler objects isn’t known a priori, they can be configured dynamically. The chaining mechanism uses recursive composition to allow an unlimited number of handlers to be linked (Source Making, Chain, 2017)
In the observer pattern, the FakeServer had a list of references to the many observers. In other words, the server object was responsible for maintaining a list of its observers as well as performing server actions. This could potentially lead to a violation of the Single Responsibility Principle if the observer management gets too complicated.
This chain of responsibility simplifies the connections between the receiving objects by moving some of the management responsibility to the receiving objects themselves. In this pattern the FakeServer only has a reference to one receiving object (the top of the chain of responsibility). When an action occurs that requires a logging statement, the server object will notify the receiving object similar to the observer pattern from above. The receiving object will act on the notification if necessary and then pass the notification down to its child. The notification will continue getting passed down the chain of receiving objects until some stop condition is triggered or the chain has ended.
A UML diagram of the chain of responsibility pattern is shown below (Wikimedia, Chain, 2013). This source uses the term “Handler” for a receiving object.
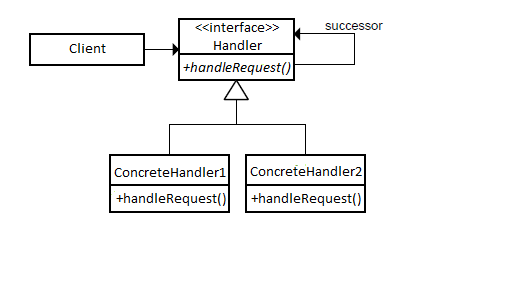
Once again, a protocol between the client and concrete handlers ensures polymorphism in the code.
Logging Implementation
The FakeServer class is now initialized with a reference to a single logger. Although I hard code the logger in this example, the reference can be created through dependency injection (just like in the observer pattern). The server no longer requires a notifyObservers method, but instead simply calls the logger’s takeAction method. The logger will write to a log file and then pass the alert down to its child. Swift optionals allow for an elegant implementation of this type of logging due to the fact that one does not need to write extra logic to detect the end of the chain.
Just as in the observer pattern, one can pass arguments down the chain and let the different loggers conditionally print log statements. In the example below, I pass a flag down the chain of responsibility.
Similar to the observer pattern, the chain of responsibility pattern removes excess print statements from the FakeServer object.
Discussion
Each of these design patterns have a distinct set of advantages in the construction of a logging system. The observer pattern results in a simple Logger protocol and Logger objects. The objects in the examples above contain only one method apiece which are called using the notifyLoggers method in the FakeServer. This means that the Logger objects are very simple to reason about – especially if some conditional logic is used in the logging process. The downside of this pattern is that it can be difficult to add new loggers to the system without halting the execution of the server since the FakeServer class stores an array of the loggers.
Conversely the chain-of-responsibility pattern hides the details of the specific loggers from the server. The FakeServer class has no knowledge of how many loggers exist and which specific actions they are responsible for logging. Instead, the client simply sends a message to a starting point in the chain and lets the loggers pass the information on through the chain of responsibility. Those that can use the information will write to a log while those that do not will do no additional action. The downside of this pattern is that each logger is responsible for logging logic and passing messages down a chain of command. If the designer is not careful, this can lead to a violation of the Single Responsibility Principle (Martin 2008).
Both of these patterns hide the multitude of logging statements from the FakeServer class. Thus, they are both preferable to the naive implementation.
Conclusion
The observer pattern and the chain-of-responsibility pattern both provide an organized structure for a self-implemented logging system. Due to the relative simplicity of the logging objects, I would turn to the observer pattern when the set of loggers is defined at the start of the program and never changes. On the other hand, I would turn to the chain-of-responsibility pattern if I expect to add new loggers to the code during its execution. Regardless of the choice, both of these patterns offer distinct advantages over the naive implementation of a logging system. They keep the main body of the code from becoming cluttered with excessive print statements and allow for conditional logs based on the different paths of execution within the code.
References
- [Dassen 1999] Dassen, J.H.M. Debugging C and C++ code in a Unix environment. OOPWeb. 1999. Web. 2017 March 11. http://oopweb.com/CPP/Documents/DebugCPP/Volume/techniques.html
- [Lurie 2009] Lurie, Ian. Analytics: Why you still need those log files. Portent. 2009 December 31. Web. 2017 March 10. https://www.portent.com/blog/analytics/analytics-you-need-log-files.htm
- [Martin 2008] Martin, Robert. Clean Code. Prentice Hall. 1st Edition. 2008
- [Source Making, Chain, 2017] Source Making. Chain of Responsibility. Source Making. 2017. Web. 2017 March 9. https://sourcemaking.com/design_patterns/chain_of_responsibility
- [Source Making, Observer, 2017] Source Making. Observer. Source Making. 2017. Web. 2017 March 9. https://sourcemaking.com/design_patterns/observer
- [Wei 2013] Wei, Wang. Importance of Logs and Log Management for IT Security. The Hacker News. 2013 October 2. Web. 2017 March 10. http://thehackernews.com/2013/10/importance-of-logs-and-log-management.html
- [Wikimedia, Chain, 2013] Wikimedia Commons. Chain of responsibility UML diagram. 2013 February 10. Web. 2017 March 15. https://commons.wikimedia.org/wiki/File:Chain_of_responsibility_UML_diagram.png
- [Wikimedia, Observer, 2010] Wikimedia Commons. Observer Pattern. 2010. Web. 2017 March 15. https://upload.wikimedia.org/wikipedia/commons/8/8d/Observer.svg
